What concurrent Ruby looks like, twelve years after the book
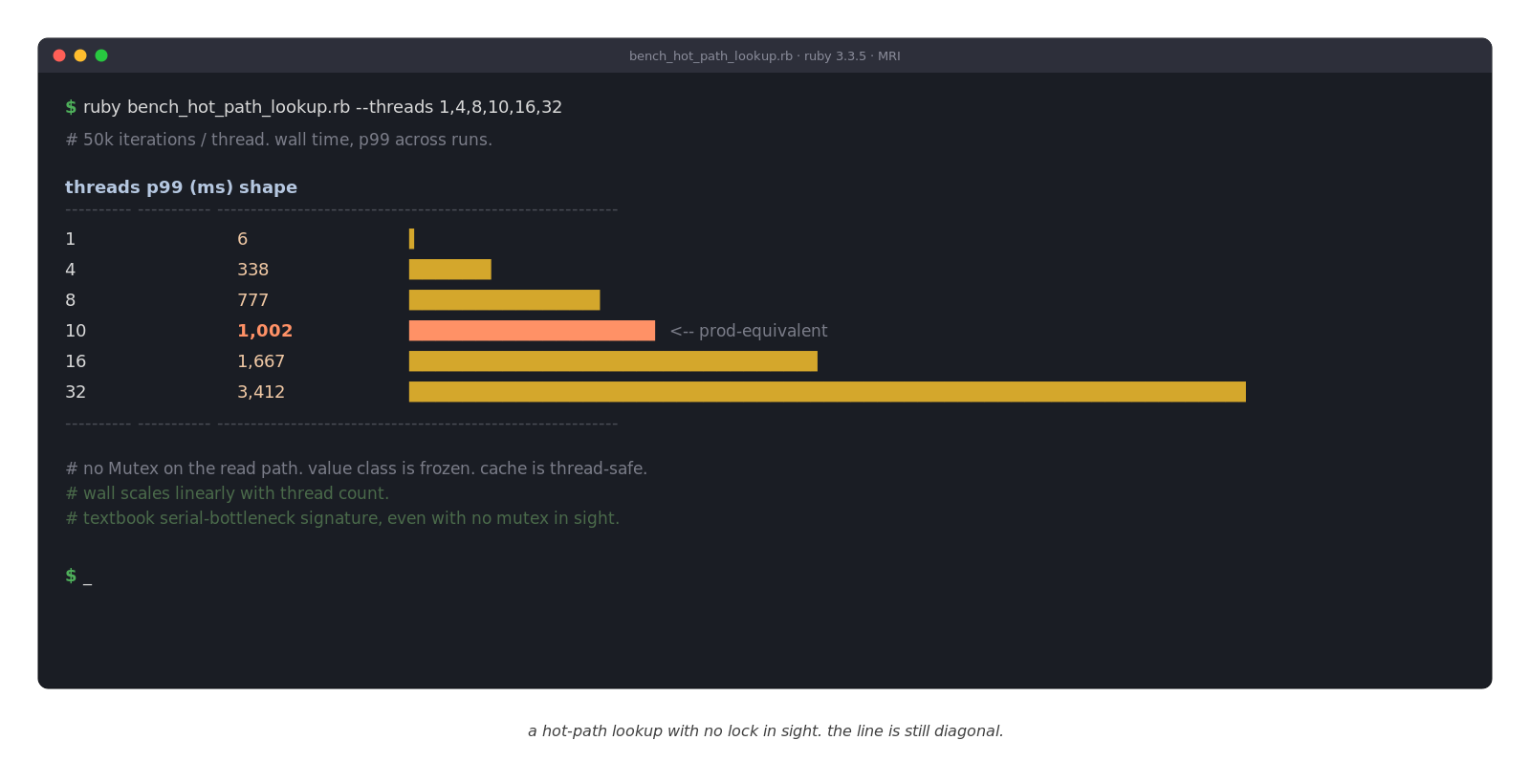
A few weeks ago I ran a benchmark on a cache read. One thread, fine. Four, fine. At ten threads the p99 was around a second. At thirty-two it was past three.
threads p50 ms p95 ms p99 ms wall s
1 6.184 7.765 9.021 3.150
4 6.638 345.249 456.259 17.218
8 5.521 774.835 817.882 27.179
10 5.818 1036.983 1099.172 35.390
16 5.635 1661.889 1708.506 55.324
32 5.367 3101.961 3412.738 94.348That's the textbook diagonal-line shape that says "something in here is serialized, even though nothing in here looks serialized." The gem we were on had no Mutex anywhere on the read path. The class we were caching was frozen. The cache itself was thread-safe.
So what was actually fighting whom? That bench is what sent me back to Jesse Storimer's Working with Ruby Threads in 2026. I'll get to the answer. The more useful part of the exercise was realising how much of what's around the book has shifted. It came out in 2014. Ruby 2.1 was the new release. Celluloid was the canonical actor library. Fiber.scheduler didn't exist. Ractor wasn't on anyone's roadmap. "Use threads carefully and reach for a multi-process server" was the complete answer for parallelism.
Twelve years later the mental model still holds, but half the toolbox is new. So this post is two halves. First, the foundations the book gives you, with the actual code where oopses happen. Then what's shown up since, and the pattern I keep reaching for when none of the obvious answers fit.
What the book teaches you, with the actual oopses
A thread in Ruby is what you'd expect from any language. An execution path with its own stack, sharing memory with the other threads in the same process. You start one with Thread.new { ... }, you wait for it to finish with thread.join, you read its return value with thread.value. The job of a thread is to let your program do more than one thing at once. Handle two web requests in parallel. Fetch two URLs concurrently. Run a background task while the main thread does something else.
The reason people get hurt by Ruby threads in particular is the GVL. Officially the Global VM Lock, sometimes still called the GIL after the Python lineage. It's a single mutex inside the Ruby VM that any thread has to hold to run Ruby code. One process, one lock, only one thread holding it at a time. The other threads aren't dead, they're just waiting their turn.
The first thing the GVL gives you is the thing people assume threads always give you: concurrency. The scheduler switches between threads, so a long-running thread doesn't freeze the rest. The second thing is what trips people up: the GVL takes away parallelism inside a single process. Two threads can't both be running Ruby code at the same wall-clock instant. They can interleave. They cannot literally co-execute.
The trick that makes multi-threaded Ruby servers work at all is that the GVL releases on blocking I/O. When a thread calls Net::HTTP.get or hits a slow database query or reads from a socket, the VM hands the lock to whoever is waiting and lets the original thread sleep until the OS wakes it back up. So a Puma worker with five threads can hold five slow database queries open in parallel, even though none of those threads is executing Ruby. The Ruby part is sequential. The I/O part is parallel.
This is why you'll hear people say "MRI gives you concurrency, JRuby gives you parallelism." JRuby and TruffleRuby don't have a GVL, so threads in those Rubies run actually-in-parallel on multiple cores. For CPU-bound work, that's a real difference. For I/O-bound work, MRI threads and JRuby threads behave nearly identically.
The GVL prevents most kinds of native-data-structure corruption. Two threads can't both be halfway through resizing the same hash. What it does not prevent is what trips you up in real code, which is everywhere the VM gives up the lock between two operations you assumed would be atomic.
Naive memoization is a check-then-act race
This is the one I see junior Rails engineers fall into all the time, because the lock makes it look safe.
class Cache
def get
@value ||= expensive_compute
end
end@value ||= expensive_compute desugars to a load, a nil check, a method call, and an assignment. The thread scheduler can switch between any of those four steps. Two threads can both read @value and find nil. Both call expensive_compute. Both assign. You do the work twice. If expensive_compute has a side effect (writes a row, books a slot, hits an external API) you do it twice. The last-write-wins assignment is silently dropping one of the results.
The fix is eager initialization at boot, or Mutex#synchronize, or Concurrent::Map keyed by whatever key you'd memoize against.
The counter race
The other one every Ruby concurrency tutorial starts with, because it's the smallest demonstration of a check-then-act race.
@counter = 0
threads = 5.times.map do
Thread.new do
temp = @counter
temp = temp + 1
@counter = temp
end
end
threads.each(&:join)
puts @counter
# => 3 or 4 or 5, depending on how the scheduler interleaves.The GVL doesn't save you. Between temp = @counter and @counter = temp, the scheduler can switch out, run another thread to completion, and switch back. Your temp is stale. Your final assignment overwrites whatever the other thread published.
@counter += 1 has exactly the same problem. So does Array#<< on a shared array, and Hash#[]= on a shared hash, and any other read-then-write you've come to think of as "atomic" in single-threaded code. Reach for Mutex#synchronize around the mutation. Reach for Concurrent::AtomicFixnum if it's literally just a counter. Reach for an immutable rebuild if the data structure is small.
Deadlock
The bug everyone has heard of and has trouble reproducing, because it needs two locks and an unlucky scheduler interleaving. The smallest example is two threads taking two locks in opposite orders.
m_a = Mutex.new
m_b = Mutex.new
Thread.new do
m_a.synchronize do
sleep 0.01 # give the other thread time to take m_b
m_b.synchronize { puts "got both, A then B" }
end
end
Thread.new do
m_b.synchronize do
sleep 0.01
m_a.synchronize { puts "got both, B then A" }
end
endBoth threads hold one lock and want the other. Neither releases. The program hangs forever. There's no Ruby-level exception, no log line, no signal. The process just sits there with two stuck threads, and you find out about it by accident, usually when a deploy gets stuck because a worker isn't draining.
The remedy is a lock hierarchy. Decide once which order locks are taken in. If m_a always precedes m_b, two threads can both ask for both and only one ever gets m_a first. The other waits. No cycle.
Livelock
Deadlock has a more humiliating sibling that happens less often but ruins your day harder when it does. To get to it you first need Mutex#try_lock, which is the non-blocking cousin of Mutex#lock. Where synchronize blocks until the lock is yours, try_lock looks at the lock, returns true and takes it if it's free, returns false immediately if someone else has it, and never waits. People reach for try_lock because it sounds like a clean defense against the deadlock pattern above: take one lock, try the other, give up and retry from the top if the second one is taken. The retry loop is what eats you.
loop do
m_a.synchronize do
if m_b.try_lock
# ... do work ...
m_b.unlock
break
end
# m_b was taken. Release m_a, try again from the top.
end
# No sleep. No backoff. Both threads spin.
endTwo threads doing this, both taking m_a, both finding m_b busy, both releasing m_a, both retrying. Forever. The program runs at 100% CPU and makes zero progress. The fix is exponential backoff, or just don't try_lock-loop. Take the locks in order and block.
ConditionVariable
This is the primitive you reach for when one thread needs to wait until another publishes something. It's the building block under most thread-safe queues.
require 'thread'
results = []
m = Mutex.new
cv = ConditionVariable.new
producer = Thread.new do
10.times do |i|
sleep 0.1
m.synchronize do
results << i
cv.signal
end
end
end
consumer = Thread.new do
10.times do
m.synchronize do
cv.wait(m) while results.empty?
puts results.shift
end
end
end
[producer, consumer].each(&:join)The two things you'll get wrong on first attempt: cv.wait(m) releases the mutex before it sleeps and reacquires when signalled, which is the whole point. And the while results.empty? has to be a while, not an if, because spurious wakeups happen and because by the time you reacquire the mutex another consumer might have shifted the result out.
Sidekiq, and why its architecture is the worked example
Sidekiq is the multi-threaded background job system that pretty much every production Ruby application reaches for, and the book devotes a chapter to walking through how it's built because it's the cleanest worked example in the language of the primitives we just covered. The shape it draws is still the shape you'd draw today if you sat down to design a job runner from scratch in 2026.
There are three classes worth understanding. The Manager is the central coordinator. It owns the hash of ready Processor threads, tracks which ones are currently busy on a job, and decides when there's spare capacity to ask for more work. The Fetcher is the single thread whose job is to talk to Redis: it does a blocking BRPOP (Redis's "give me the next item, wait if there isn't one yet"), pulls a job off the queue, and hands it to a Processor. The Processor is one of N worker threads that actually runs the job code.
What makes the design clean, and what the book is teaching you with it, is that each component's mutable state lives inside exactly one thread. The Manager mutates its busy-set. The Fetcher mutates its own Redis connection. Each Processor mutates only the job it's currently running. Cross-thread communication happens through Queue and ConditionVariable, which are exactly the primitives we built up in the sections above. Redis is the durable queue that everything else hangs off of, surviving process restarts and crashes that an in-memory queue wouldn't.
The lesson the book is teaching, and the one that holds up unchanged in 2026, is that you don't get to thread-safe Ruby by sprinkling Mutexes over an existing design. You get there by deciding ahead of time who owns each piece of mutable state and never letting anyone else touch it directly. The Manager / Fetcher / Processor split is that decision made architecturally, before any locks get added.
What the book doesn't cover
This is the section I went looking for and couldn't find written down anywhere in one place. So here goes.
Ractors, and what they still don't fix
The biggest new thing in MRI concurrency since 2014 is the Ractor, introduced in Ruby 3.0 in late 2020. A Ractor runs Ruby code in true parallel with other Ractors. Each one has its own lock. Two on a two-core machine can crunch numbers at the same time.
worker = Ractor.new do
loop do
msg = Ractor.receive
Ractor.yield msg.upcase
end
end
worker.send("hello")
puts worker.take # => "HELLO"The constraint that wins every argument about Ractor adoption is the shared-state one. Ractors can't share most mutable state. Send an unshareable object and you get an error at runtime.
state = { count: 0 }
worker.send(state)
# Ractor::IsolationError: can not send unshareable objectTo pass it, you have to Ractor.make_shareable(state) first, which deep-freezes it. Or you pass it as a move-send, which transfers ownership and revokes your local reference. No shared connection pool, no shared logger, no shared in-memory cache. Jean Boussier (byroot) on the Shopify infrastructure team put it bluntly a few years back: this is "a major architectural challenge that would require most libraries to be heavily refactored, and the result would likely not be as usable."1
Ruby 4.0, out Christmas 2025, is the most-improved Ractor release so far. The API got a real overhaul: Ractor::Port is the new class for inter-Ractor send-and-receive communication, and the older Ractor.yield and Ractor#take methods that did the same job in 3.x are gone in 4.02. Internally, several VM-level data structures that used to be shared across all Ractors (and therefore had to be protected by a global Ractor-level lock during access) have been reworked to either be lock-free or to be split per-Ractor3. The specific ones are mostly things the application engineer never touches directly: the symbol table that holds interned Ruby symbols, the method cache the VM uses to dispatch method calls, the per-process counter that tracks how many objects have been allocated. Each of those used to be a serialization point between Ractors, and getting them off the global lock is the work that pushes "Ractor in production" closer to plausible.
The release notes still carry the line that's been there since 3.0: "Ractor was first introduced in Ruby 3.0 as an experimental feature. We aim to remove its 'experimental' status next year."3 That sentence has now appeared in five consecutive release announcements, which tells you something about the gap between the roadmap and "production-ready for a Rails monolith with two hundred gems in the Gemfile."
For greenfield CPU-bound problems (a parser, an image pipeline, a self-contained simulation) Ractors are genuinely useful. What they haven't done, and no one seriously expects them to do in 2026, is replace the fork-per-core deployment model for application servers. The pull of "every gem in the Gemfile has to be Ractor-safe" is too strong.
Fiber.scheduler and async
Quieter shift, and I think the one actually changing how new Ruby code gets written: the Fiber scheduler interface that landed in Ruby 3.0 alongside Ractor. Fibers themselves have been in Ruby since 1.9, but until 3.0 they were cooperative-only inside your own code. The Fiber scheduler hook lets a third-party library register itself with the VM so that blocking I/O operations (a Net::HTTP call, a read on a socket, a sleep) automatically yield to other fibers instead of blocking the whole thread.
Samuel Williams's async4 is the library that wires this up. The code looks synchronous. The runtime is event-driven.
require 'async'
require 'net/http'
Async do
urls = (1..10).map { |i| URI("https://example.com/#{i}") }
urls.map do |url|
Async { Net::HTTP.get(url) }
end.map(&:wait)
end
# 10 concurrent HTTP requests, in one thread, no threadpool.
# Each Async block runs as a fiber. The blocking Net::HTTP.get
# yields to the scheduler. The scheduler resumes the next ready fiber.Fibers are kilobytes of stack instead of megabytes, so one process can hold tens of thousands of them. And because fibers cooperate rather than preempt, there's no GVL contention between in-flight requests inside one fiber-scheduler-driven thread. The cost is on you. CPU work inside a fiber holds the scheduler until it yields, so a chatty fiber starves its siblings. Ruby 4.0 added Fiber::Scheduler#fiber_interrupt for cancelling a fiber stuck on a now-closed IO, which patches one of the rougher edges in the 3.0 interface5.
Then there's Falcon6, also from Williams, the Rack-compatible server built on async. Multi-process for parallelism across cores, multi-fiber inside each worker for I/O. For workloads that are genuinely I/O-bound, especially streaming and WebSockets, the production reports are consistent. A single Falcon worker holds many more simultaneous long-lived connections than Puma can, because Puma costs a thread per connection and fibers don't.
The transparency claim is more nuanced than it first reads. What the scheduler hooks into is Ruby's standard I/O surface: Net::HTTP, socket reads and writes, Kernel#sleep, IO#wait_readable, the things that go through rb_io_wait and rb_thread_schedule. A C extension that blocks in rb_thread_call_without_gvl without scheduler awareness, or that does its own native syscall, will block the whole thread regardless of how many fibers want to run. The canonical case is the pg gem, which is not scheduler-aware out of the box. So "same Net::HTTP, same Kernel#sleep" is the accurate claim. "Same every gem in the Gemfile" is not.
I haven't run Falcon in production. I want to. The honest blocker is the same as Ractor's. The gem ecosystem assumes thread-based concurrency. If your background-job adapter, your APM agent, your feature-flag client, or your DB driver assumes thread-local state where the right answer is fiber-local state, you'll find out at the wrong moment.
concurrent-ruby and the small primitives
concurrent-ruby is a Ruby gem that ships the set of thread-safe data structures and synchronization primitives the standard library leaves out, and it shows up in most production Ruby codebases (including ones that haven't gone near Ractors or Fibers). Rails has depended on it for years. Most of what it ships is a direct port of the equivalent primitive from Java's java.util.concurrent library, which means the contracts are well-specified and the failure modes are well-studied by twenty years of Java concurrency literature.
The handful worth knowing by name. Concurrent::Map is a thread-safe hash. On JRuby and TruffleRuby it's lock-free on reads with per-bucket locking on writes, so two threads reading different keys never block each other. On MRI it falls back to a synchronized Hash, which is slower but still correct, and importantly does not require you to wrap every access in your own Mutex#synchronize block the way a plain Hash would. Concurrent::AtomicFixnum is the right primitive for the counter race we walked through earlier, where the read-then-write on a shared integer kept losing increments. Concurrent::Promise is the gem's take on the Promise pattern from JavaScript and java.util.concurrent.CompletableFuture: a value that will exist at some point in the future, with .then and .rescue chaining for composing async work without callbacks. The thread pools (Concurrent::ThreadPoolExecutor and the bounded-queue variants) are the right answer when you want fan-out work without unbounded thread allocation, because the bounded queue gives backpressure when the pool is saturated.
Concurrent::AtomicReference is the one worth pulling out separately, because the rest of this post hinges on it. The contract is simple: it holds a single object reference, and AtomicReference#update { |old| new } publishes a fresh reference such that any other thread either sees the old value or the new value, never a half-published torn write. That's the primitive you reach for when the read-side hot path should do zero allocations and zero locking, and the write-side cold path occasionally swaps in a new immutable snapshot of the world.
The GVL debate, and what's actually moving
"Remove the GVL" is a proposal that surfaces on Ruby-core every year or two as something somebody seriously argues for, and the most thorough treatment I know of is Jean Boussier's "So You Want To Remove The GVL?"7. The piece uses the recent Python experiment as a worked comparison. Python 3.13 shipped an optional "free-threaded" build with the GIL turned off, and the work it took to get there was enormous. To make Python safe without a single global lock the interpreter had to add per-object locks for shared structures, double the size of object headers to hold the lock-state metadata, and switch reference counting to atomic operations on every increment and decrement so two threads couldn't corrupt the count. The short version of Boussier's argument is that doing the equivalent in Ruby would be similarly expensive, would slow down single-threaded performance for code that doesn't need parallelism, and might not buy as much in real production workloads as people imagine.
The cheaper wins, per Boussier and John Hawthorn, sit one layer below "rip out the lock entirely." The first is a smarter thread scheduler. Ruby's current scheduler is FIFO with no notion that an I/O-bound thread that just woke up from a socket read should get the lock back faster than a CPU-bound one that's been hogging it. The second is widening the windows where the GVL is released during C-extension work, so threads inside those gems don't serialize each other unnecessarily. Aaron Patterson shipped a small but useful piece of the first direction in Ruby 3.4: an environment variable exposing the thread-switching quantum, which is the maximum time slice one thread is allowed to hold the lock before the scheduler considers handing it over. The default is 100ms, and now workloads that have measured their contention can tune it8.
The other moving piece in the same neighbourhood is the JIT story. A JIT (just-in-time compiler) is a part of the language runtime that watches your code at runtime, identifies the hot paths, and emits faster machine code for them on the fly. Ruby has shipped two JITs that matter. YJIT is the production-grade one written in Rust by the Shopify performance team and has been the default JIT since Ruby 3.3. ZJIT is the next-generation method-based JIT in Rust that Ruby 4.0 introduced. It's slower than YJIT today, but the design is intended to be the long-term replacement9. Neither JIT changes the GVL or the lock structure. What they both do is make the work that runs under the lock cheaper, which means there's less contention to fight in the first place.
The pattern I keep coming back to
Now back to the bench at the top of this post.
The method under test was a cache lookup. Roughly this shape:
def find_cached(scope, key)
cache_key = build_key(scope, key) # composes a small object
CACHE.fetch(cache_key) do
load_and_freeze(scope, key) # cold path, almost never runs
end
endEvery request calls find_cached a few dozen times. The hot path is the CACHE.fetch line returning an already-loaded, deeply-frozen object. By every reasonable model of "what is this code doing," the body of find_cached should cost a microsecond on a warm cache. One thread saw exactly that. Ten threads saw a p99 around a second. Thirty-two threads saw three.
So I went down the obvious list.
Is the cache itself locked? No. CACHE is Concurrent::Map, which is read-lock-free on MRI by construction. Its reads do not block each other.
Is the cached object hot? No. The value is a frozen class. Once it's in the map, nothing mutates it. No Mutex anywhere on the read side, no instance state being read under contention.
Is something inside load_and_freeze running on every call? Also no. I traced it. The block on fetch only fires when the key is missing, which on a warm bench is never.
By that point the only thing left in the method was build_key. Which is, roughly, this:
def build_key(scope, key)
{ scope: scope, key: key }.freeze
endThat's the line. Three allocations per call. A small Hash, two Symbol-keyed entries, a freeze. Innocent in the single-threaded reading of the code. Concurrently, it was the entire bottleneck.
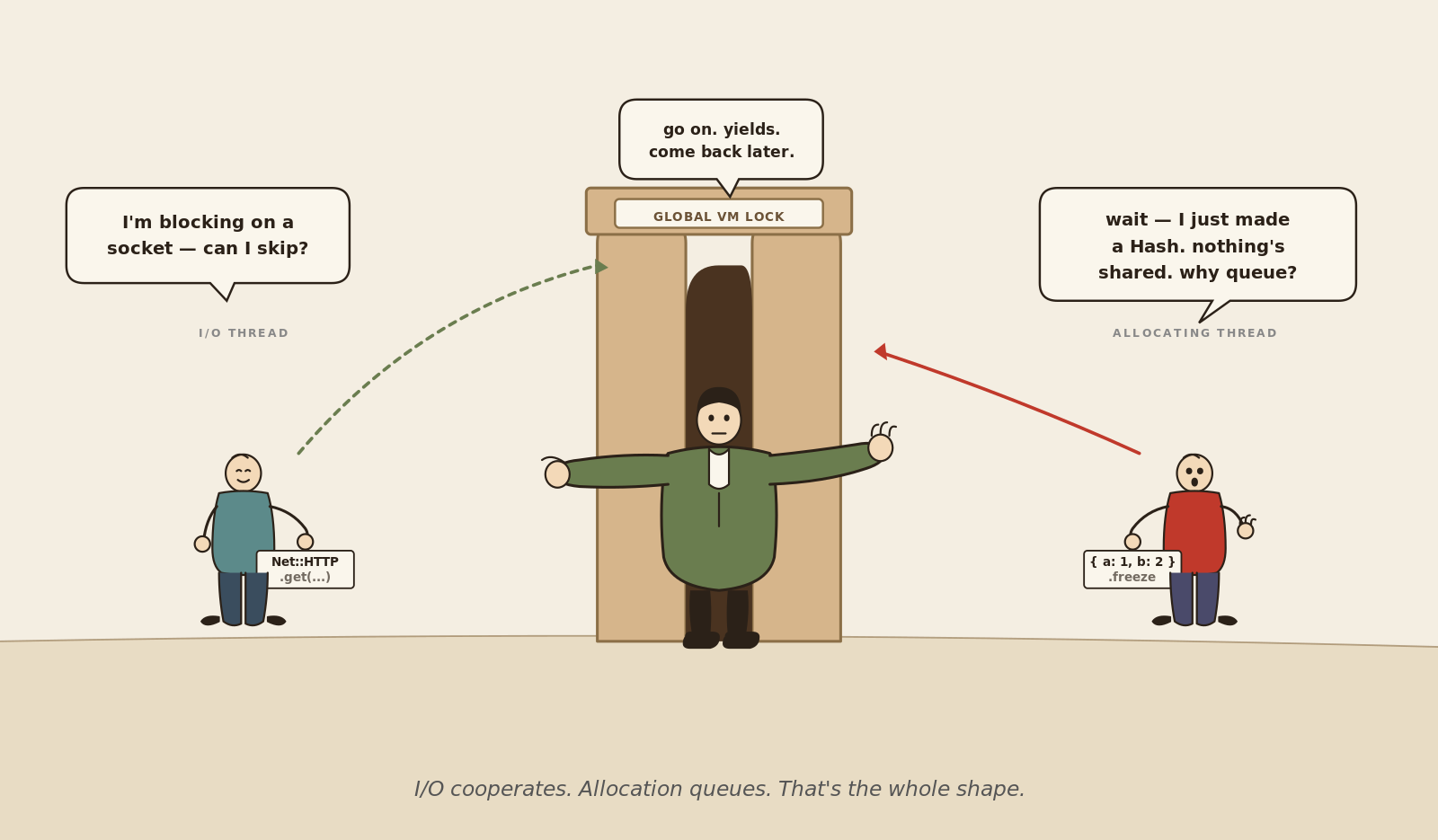
When a thread does an I/O call like Net::HTTP.get, a slow Postgres query, or a socket read, the VM hands the GVL to another thread and lets the first one sleep. The blocked thread costs nothing while it waits. That's what makes a ten-thread Puma worker actually serve ten concurrent requests against a slow database.
When a thread allocates a Ruby object, the VM does the opposite. It does not release the GVL. The allocation runs to completion under the same lock you're already holding. If the allocation triggers a minor GC (Ruby's compaction-friendly young-generation collector), the GC runs under the GVL too. Every other thread that wants to do anything in Ruby, including returning from a finished I/O wait, has to wait for that GC to finish before it gets the lock back.
Now picture ten threads, each calling find_cached a few dozen times per request. Each call makes three small objects. Most of those allocations are fast and free. Occasionally, one of them tips Ruby's young generation over the threshold and triggers a minor GC. That GC pauses every Ruby thread in the process, not just the one that allocated. The more threads you run, the more often any one of them tips the threshold, the more often everyone else pays for it. The bench's p99 wasn't measuring find_cached. It was measuring the queue of threads waiting for the GC that one of them just triggered.
The cache was fine. The frozen object was fine. The thing that was "shared" was the allocator, and nothing in the code looked like it.
I went back to first principles and asked myself what the read-side should look like if it really had to do zero work per call. The answer was a pattern I'd seen in Java and Go forever, and that's perfectly idiomatic in Ruby with concurrent-ruby. Pre-warm once at boot. Store the result as a deeply-frozen object behind a Concurrent::AtomicReference. Have the read path do ref.value and nothing else. No allocations, no locking, no synchronization beyond the atomic load itself, which on any modern CPU is a few nanoseconds.
SNAPSHOT = Concurrent::AtomicReference.new(build_snapshot)
def lookup(key)
SNAPSHOT.value.fetch(key)
end
def refresh!
SNAPSHOT.update { |_old| build_snapshot }
endThere's no cleverness here. That's the point. Every piece of cleverness got pulled out of the read path and pushed to build_snapshot. That method walks the source of truth, builds a Hash keyed by whatever the lookup needs, deep-freezes it, returns it. The atomic swap means a refresh! running in one thread is observed by every other thread on its next read, with no half-mutated state visible in between. Reads are pure, allocation-free, lock-free.
After the swap, the bench came back microseconds across every thread count.
You can apply this anywhere the read pattern is "look something up many times per request" and the write pattern is "occasionally swap in a new version of the whole dataset." It's the same pattern the per-request feature-flag dial in my earlier ConfigMap post reaches for one level up. The channel announces "something changed". A background thread does the cold work of rebuilding the snapshot.
What this doesn't fix is the case where the read has to do real work. If your read has to compose a result from three different sources, or if the dataset is too big to hold whole in memory and you're caching subsets, the snapshot trick isn't the right move. The right move there is closer to what Concurrent::Map gives you. A thread-safe hash with per-bucket locking. Slower than the atomic reference on the read side, but it lets you mutate in place.
What I'd still revisit
Ractor adoption is the big one. The plausible path isn't "rewrite the application around Ractors". It's "one or two narrow, CPU-bound subsystems get a Ractor boundary around them and stay there." If you've actually shipped a Ractor in production for a Rails monolith and it worked, I'd want to hear about it. Every story I've seen so far has been a yak-shave that ended in "we put it back behind a thread."
Where Falcon belongs is the other one. The case for fiber-based servers is overwhelming for streaming and WebSockets. The case for ordinary request-response Rails is more nuanced, and likely lands at "Falcon for the things that look like real-time, Puma for everything else, in the same fleet." My own next step is to put a small streaming endpoint behind Falcon and measure.
The GVL-removal question I think is mostly answered for now. The improvements Ruby actually needs (smarter scheduler, longer GVL-released windows during DB work, more parallelism in the GC) aren't blocked on the lock. They're separate work, and they're the work I'd bet on shipping in the next few releases.
If you've hit a different shape of this same problem, or you're running Ractors or Falcon in production and want to compare notes, I'd love to hear about it. [email protected]. The war stories are the part I read first.
Footnotes
-
Jean Boussier, To Thread or Not to Thread, Shopify Engineering. The Ractor section is the cleanest articulation of the "global mutable state is the bottleneck" framing I've read, and it predates Ruby 4.0 but holds up. ↩
-
Ruby 4.0.0 release notes, Compatibility issues / Ractor. The removed methods are
Ractor.yield,Ractor#take,Ractor#close_incoming, andRactor#close_outgoing, all replaced byRactor::Port. ↩ -
Ruby 4.0.0 release notes, Ractor Improvements and Implementation improvements / Ractor. The lock-free hash set for the frozen-string table and the per-Ractor allocation counter are the two changes I'd flag as the most operationally meaningful. ↩ ↩2
-
socketry/async, readme. The project description is "composable asynchronous I/O framework for Ruby based on io-event," and the guides on scheduler, tasks, and thread safety are worth reading in order. ↩
-
Ruby 4.0.0 release notes, Fiber::Scheduler section.
Fiber::Scheduler#fiber_interruptis the one I'd point at. The original 3.0 interface had no clean way to cancel a fiber waiting on a closed IO. ↩ -
socketry/falcon, readme. The architecture description ("multi-process, multi-fiber rack-compatible HTTP server built on top of async") is the one-line summary that explains every operational property below it. ↩
-
Jean Boussier, So You Want To Remove The GVL?. The comparison with Python's per-object lock implementation is the part I keep going back to when someone says "just remove it like Python did." ↩
-
Ruby bug tracker, Feature #20861: Make the thread time quantum configurable. Aaron Patterson's change to expose the 100ms quantum as an env var. Not a fix, a knob, but a useful one if you've already characterised your contention. ↩
-
Ruby 4.0.0 release notes, JIT / ZJIT and the Rails at Scale ZJIT launch post. The Rails at Scale post is where I went for the "why a new JIT and not more YJIT" explanation. ↩
Comments